拓谷思年度独立站+SEO大会回顾

有人的地方就有江湖,在爬虫的世界里也是一样。很多新手同学的爬虫简单粗暴,不管对端服务器的压力,直接多线程、多进程爬虫疯狂搞事。
服务器端
你要搞事是吧?我就不让你搞事!
爬虫
你不让我搞事是吧?我偏要搞事!

于是就有了反爬虫,有反爬虫就有反反爬虫,有反反爬虫就有反反反爬虫…

在看了前几期文章后有很多小伙伴已经能自己敲出指哪儿爬哪儿的爬虫了,却被亚马逊的反爬虫所困扰。爬着爬着弹个验证码、不返回正常数据,咋整?
所谓道高一尺魔高一丈,下面将为大家列举亚马逊的几种反爬手段及解决办法!
Headers是什么?
首先要说明一下HTTP是“Hypertext Transfer Protocol”的所写,整个万维网都在使用这种协议,几乎你在浏览器里看到的大部分内容都是通过http协议来传输的, 而Headers是HTTP请求和相应的核心,它承载了关于客户端浏览器,请求页面,服务器等相关的信息。
下图就是访问https://www.amazon.com/时的Request Headers:
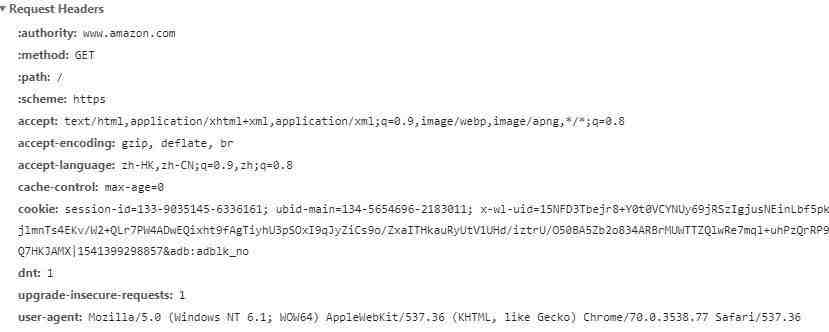
其中包含了authority、cookie、user-agent等字段。
1、通过User-Agent字段来反爬
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
标准格式为: 浏览器标识 (操作系统标识; 加密等级标识; 浏览器语言) 渲染引擎标识 版本信息。
大多数网站都会在后台的根目录下放置一个名为“robots.txt”的文件,在这个文件中规定了某些特定的User-Agent哪些页面可以访问,哪些页面不可以访问。如亚马逊美国站的“robots.txt”地址为:https://www.amazon.com/robots.txt,大家可以访问看一看。robots.txt一般称为robots协议,可以说是一个君子协议,遵不遵守还看个人。我们可以考虑收集一堆User-Agent的方式,或者是随机生成User-Agent,达到伪造User-Agent的目的,即可解决这种反爬手段。
2、 通过referer字段或者是其他字段来反爬
Referer记录了你是从什么网站跳转到该网站的。比如通过Google搜索到Amazon.com,再点击跳转,那么本次请求中的headers中就会包含Referer:http://www.google.com,表示你从谷歌跳转而来。通过referer字段反爬,一般在针对图片、视频、音频资源时出现较多,当你访问这些资源时,服务端检查你的referer字段非正常便会给你返回一些假资源,如我们早年玩儿的QQ空间、天涯社区针对图片资源反爬出现的“盗链图片”:

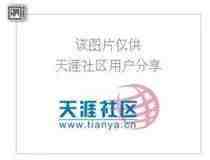
通过referer字段反爬,我们也可以在headers中伪造referer字段来解决。
3、 通过cookie来反爬
Cookie是网站为了辨别用户身份、进行 session 跟踪而储存在用户本地终端上的数据。如果目标网站不需要登录,每次请求带上前一次返回的cookie,比如requests模块的session,即可达到反爬目的。
如访问亚马逊美国站中ASIN为:XXX的商品,每次都带上不同的cookie,代码如下:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
'Referer': "www.google.com"
}
session = requests.session()
# 先访问亚马逊主界面拿到cookies,保持会话。
session.get('https://www.amazon.com', headers=headers)
如果目标网站需要登录的话则准备多个账号,通过一个程序获取账号对应的cookie,组成cookie池,其他程序使用这些cookie即可访问到登陆后的页面。
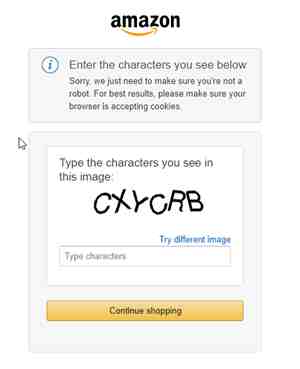
上一次prime day亚马逊全站都开启验证码,那种寸步难行的感觉不知大家还记不记得?通过验证码来反爬是大多数网站通用的一种反爬手段,比较出名的有12306、google人机测试、极验滑块等。在这些验证码面前,亚马逊验证码还是显得很照顾用户体验的,至少没弹出什么奇奇怪怪的东西让我们点选,只是单纯的4-6位字母,那么要识别它还是挺Easy的!
Python通过获取大量的验证码图片素材,使用OCR、PIL、SVM等库进行验证码图片的二值化、切割、模型训练,最终可实现对亚马逊验证码的识别。
自己用Python识别这么多步骤、
这么多东西,搞起来是不是很难?
难!肯定是要花点儿时间的!
那咋整?

有一种东西“打码平台”!把验证码图片上传给他,在规定时间内(一般60S内)就会返回识别后的验证码。
下面是某打码平台的价格表:
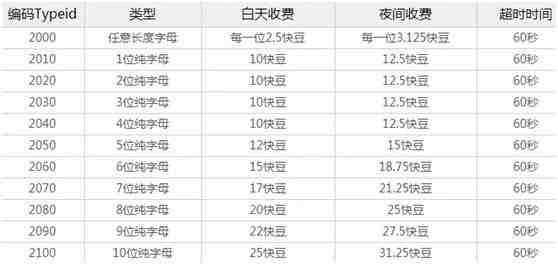
该打码平台的充值比例为1元=2500快豆,如果我们选择6位纯字母模式识别的话,1块钱就可以识别166.66次…是不是超便宜?
各个打码平台的使用方法不一,这里就不贴代码了。选定一家打码平台,联系客服或者查看开发者文档demo,轻轻松松就能通过代码的形式搞定亚马逊验证码。
当然,有实力、有兴趣的同学还是建议自己弄验证码识别,毕竟是一劳永逸的事情。
同一个ip大量请求了对方服务器,有更大的可能性会被识别为爬虫,ip就有可能被暂时拉进小黑屋。咋办?
别怕!用代理ip,完美解决这种反爬手段。
什么是代理ip?就好似你找了一个代理人,让他去访问你的目标网站,然后跟他要目标网站给他的数据
如图:
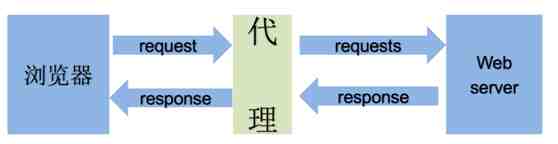
根据代理ip的匿名程度,代理ip可以分为下面四类:
透明代理(Transparent Proxy)Transparent Proxy):透明代理虽然可以直接“隐藏”你的IP地址,但是还是可以查到你是谁。
匿名代理(Anonymous Proxy):匿名代理比透明代理进步了一点:别人只能知道你用了代理,无法知道你是谁。
混淆代理(Distorting Proxies):与匿名代理相同,如果使用了混淆代理,别人还是能知道你在用代理,但是会得到一个假的IP地址,伪装的更逼真
高匿代理(Elite proxy或High Anonymity Proxy):可以看出来,高匿代理让别人根本无法发现你是在用代理,所以是最好的选择。
在使用的使用,毫无疑问使用高匿代理效果最好
从使用的协议:代理ip可以分为http代理,https代理,socket代理等,使用的时候需要根据抓取网站的协议来选择
在Python的requests库中,也早已设计了使用代理IP的方法:
import requests
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
}
requests.get("http://httpbin.org/ip", proxies=proxies)

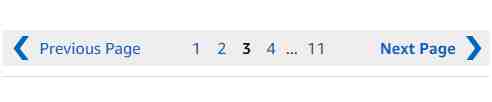
上面是亚马逊搜索页面翻页的两种前端样式,估计一般人都不会注意这里有什么变化。两种前端的代码也有所不同,如果你的爬虫只针对其中一种页面获取下一页的url,就会导致你的爬虫在遇到另外一种翻页样式时挂掉。
这也正是亚马逊的高明之处,与国内电商相比,它在照顾用户体验的同时,也达到了反爬的目的。针对这种情况我们需要在爬虫里首先判断当前页面是哪种前端样式(多写两个if…else),这样才能兼容两种样式。
以上就是本人在编写亚马逊爬虫中遇到的反爬手段,希望能对大家有一些帮助!
最后希望大家且爬且珍惜,假如只要单纯商品的详情、报价和Sales Rank,用MWS API 就好。假如用爬虫,切记不要暴力的爬!破解验证码是有风险的,假如破解后还暴力的爬,那下次亚马逊恼羞成怒,可能就换另一种更强的反爬虫机制了,到时可就没得爬咯!


我们建了一个亚马逊卖家交流群,里面不乏很多大卖家。
现在扫码回复“ 加群 ”,拉你进群。





热门文章
*30分钟更新一次