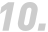深度硬核:亚马逊真实搜索量终极解密

关于亚马逊搜索量,行业争议已有五六年之久。虽然亚马逊在后台多个模块陆续披露了搜索量数据,但卖家朋友们可能并未注意,其实它们都不是真正的搜索量。
这篇文章,我们也筹备一年有余。陆续写过2篇阶段性的解密亚马逊搜索量的文档,但一直未对外发表,就是因为亚马逊的数据还有诸多矛盾和谜团未解。
但随着亚马逊近期的一个调整,我们认为时机已经成熟。搜索量这个悬而未决的问题,是时候给大家一个结论,终结行业争议了。
由于篇幅较长,我们先把结论贴在这里,暂时没时间阅读的卖家朋友可以直接记下:
现在的“搜索词表现”模块的“搜索查询数量”是真正的搜索量
商机探测器中搜索词的“360天搜索量”是搜索人数
ABA排名是PC端的搜索人数排名
有兴趣的卖家朋友则可以跟随我们一年多来的研究历程,逐渐抽丝剥茧真正的搜索量。
曾经我们以为的搜索量
都不是真的搜索量
整个研究过程十分坎坷,可谓一波三折,在经历第四波的时候,真正的搜索量才逐渐浮出水面。这三折分别是:
第一折:ABA(品牌分析)数据
第二折:商机探测器
第三折:搜索词表现1.0
换句话说,ABA、商机探测器、搜索词表现1.0这三个亚马逊后台的模块给出的数据,背后对应的都不是搜索量。直到搜索词表现2.0出现的时候,亚马逊给出的数据才看起来“像”搜索量。
之所以说“像”搜索量,是因为这里边依然有很多疑点,或者说,在亚马逊的多个模块给出的数据之间,矛盾似乎越来越多了。
本篇长文,我们会从商机探测器聊到搜索词表现1.0,再到最新的搜索词表现2.0,然后再回过头去重新审视我们已经习以为常的ABA数据,毫无保留地与大家分享我们在搜索量上的研究。
我们也会为大家逐一解密,为什么ABA、商机探测器、搜索词表现1.0不是真正的搜索量,我们又是如何逐渐洞察到真正的搜索量的。最后,我们还会与大家分享我们的搜索量模型的方法,以及使用亚马逊数据的一些实用建议,供大家参考。
文章虽长,如果大家能耐心看完,我们敢保证,一定会有非常巨大的收获。不仅能知道什么才是真正有参考价值的数据,同时对亚马逊后台的数据逻辑也会有更加深刻的认识。
文章会分五个部分逐渐展开:
关于搜索量的几个常识性认知错误
后台到底什么数据才“像”是真正的搜索量
搜索量还有什么疑点
Sif是如何做搜索量模型的,准确率如何
如何正确地认识和使用亚马逊数据
关于搜索量的三个常识性认知错误
在解读真正的搜索量之前,我们必须先指出几个常见的关于搜索量的认知错误。这些认知错误并不是大家的问题,而是因为亚马逊不严谨或不透明的数据统计所致。如果不仔细加以研究,非常容易被误导。
澄清这些错误,有助于大家真正理解这些看起来是搜索量实际上并不是搜索量的数据到底代表什么含义,避免被误导,做出错误的决定。
错误一,认为商机探测器里的细分市场是真实搜索量
这个问题在商机探测器刚开始出来的时候,有大量用户没经过仔细研究,就误以为是搜索量。这个错误并不严重,很快大家就认识到商机探测器给出的是同类商品聚合之后代表的细分市场,也就是某类需求的代名词,而不是单个关键词。
错误二,认为商机探测里的搜索词是真实搜索量
细分市场的搜索量不是关键词的搜索量,但是细分市场的二级菜单里,有一个“搜索词”模块,这个里边是具体的关键词,所以很快,大家就认为这个是真实搜索量,并在很长的一段时间里深信不疑。我们跟很多研究过这个数据的大佬交流,他们都认为是。
但做数据分析的直觉告诉我们,这个数据应该也不是搜索量,因为按照这个数据做推断,亚马逊的GMV体量,要比实际的小好几倍。
但这个问题并不好证明,因为我们的推断模型引入了其他变量,这些变量的值也存在一定的不确定性。但我们坚信,这个数据从直觉和逻辑上说不通。
于是我们选择了默默的顶住压力,不对搜索量模型做出调整。即便一些友商为了讨用户欢心,逐渐将搜索量改成了和商机探测器保持一致,但我们依然不为所动,因为我们相信那不是真正的搜索量。
转机出现在亚马逊推出了搜索词表现1.0,逐渐开始证明我们的坚持是对的,这也是错误三的由来。
错误三,以为搜索词表现1.0里的搜索量是真实搜索量
亚马逊并没有将搜索词表现模块划分过1.0和2.0版本,这是我们自己的划分。之所以这么划分,是因为亚马逊对搜索词表现做过改版,改版前和改版后的数据有比较大的出入。且1.0版本中出现过一个极其重要的数据,正是这个数据,让我们开始逐渐挖掘到真正的搜索量,并据此逻辑严密地证明了商机探测器里的搜索量不是真的搜索量。
为了给大家真实还原我们的研究过程,我们把改版前称为1.0版本,改版后称为2.0版本。
在1.0版本中,我们挖掘到了一些表征搜索量的隐含数据。这个隐含数据来自于搜索词表现数据内部多个字段间的矛盾。
很多卖家应该没注意和留存过这个中间版本的数据,所以我们在这里贴一些出来,让大家对我们的研究过程有更真切的感受。
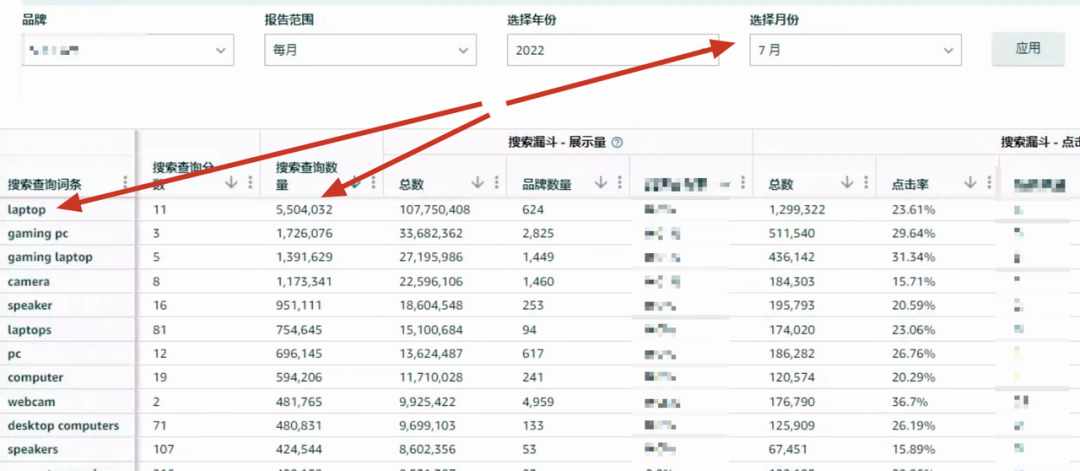
我们先给大家看一下原始数据。在1.0版本的时候,我们下载了2022年7月份的搜索词表现数据,并做了简单的整理,我们主要关注搜索查询数量、点击量、点击率、加购量、加购率、购买量、购买率这7个数据。
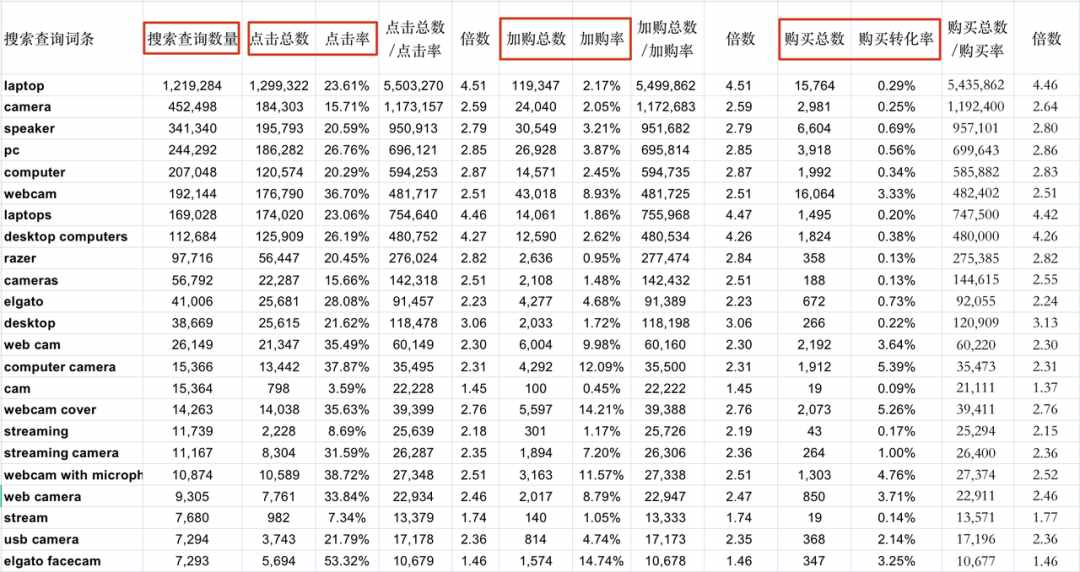
我们将点击量/点击率、加购量/加购率、购买量/购买率两两相除,得到另外三个指标,如下图所列。
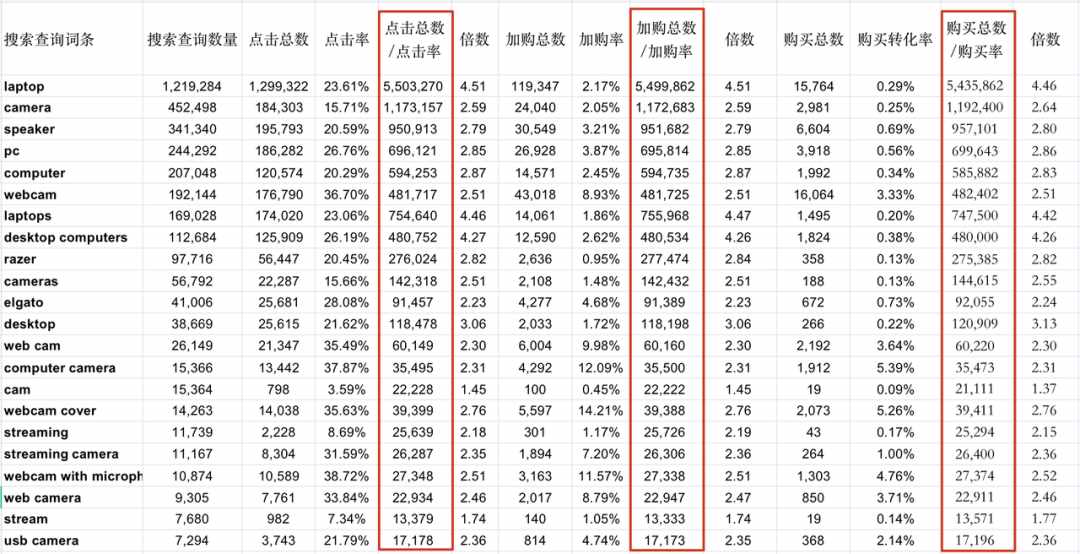
这三列数据很有意思,同一个关键词下,它们的值非常接近。
我们猜测,同一行这三列数值其实应该是同一个数字,之所以不完全相等,是因为亚马逊在计算点击率、加购率、购买率的时候只保留了2位小数,我们还原回去的时候会因为省略的小数位数,带来一定误差。
我们还猜测,点击量/点击率、加购量/加购率、购买量/购买率这三组比值,得到的都是同一个值——搜索量。
为什么是搜索量?我们先做一下逻辑上说明,然后再用数据证明。
亚马逊的电商数据,在全球范围内有诸多类似的应用。其中转化漏斗数据的计算,全世界通常有两种方法:
一个是将转化漏斗的第一个环节的变量,作为所有后续指标的固定分母,比如当第一环节是搜索量的时候,那么后续的所有点击率和转化率都以搜索量为分母,得到搜索点击率和搜索转化率。这是在衡量市场数据的时候更常使用的一种标准,也是亚马逊现在很多市场数据在使用的标准。搜索词表现,我们认为就是这种计算方法。
另一个标准是转化漏斗的下一环节除以上一环节,比如大家习惯的点击率是点击量/曝光量,转化率是购买量/点击量。这种计算方式一般是在计算卖家自己的数据时更常用的标准,方便你评估在你自己的转化流程里,每个环节的转化(和对应的流失)是什么水平。大家自己产品的广告数据就是这种计算方法。
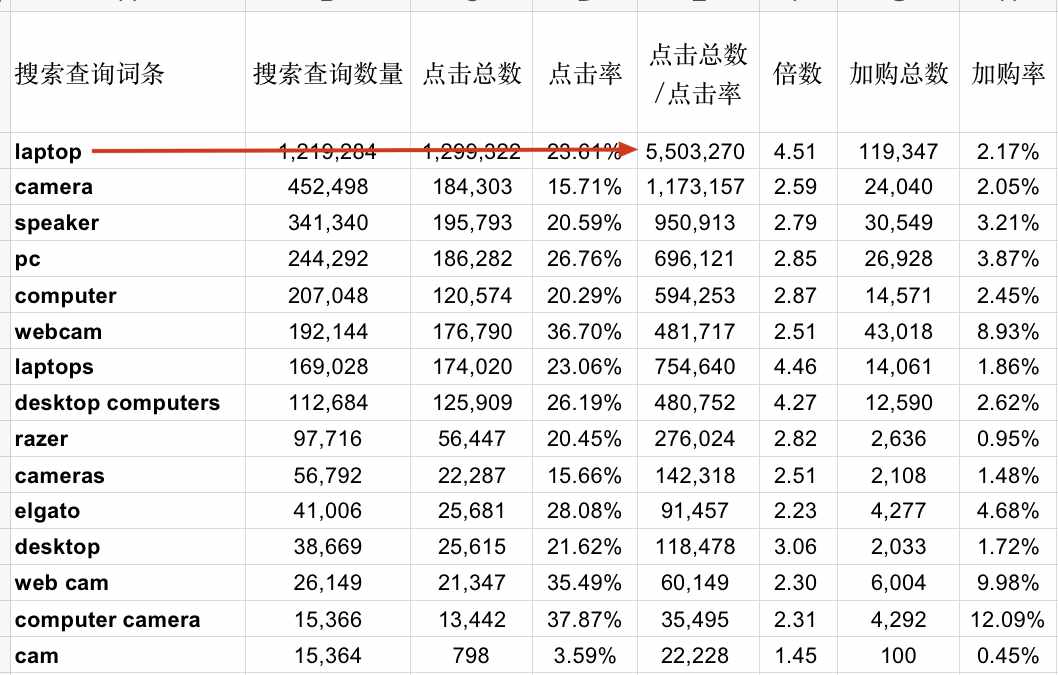
假设这三个值可能代表搜索量,而亚马逊也直接给了一个搜索查询数量,我们分别用这三组数据与搜索查询数量做一下对比。
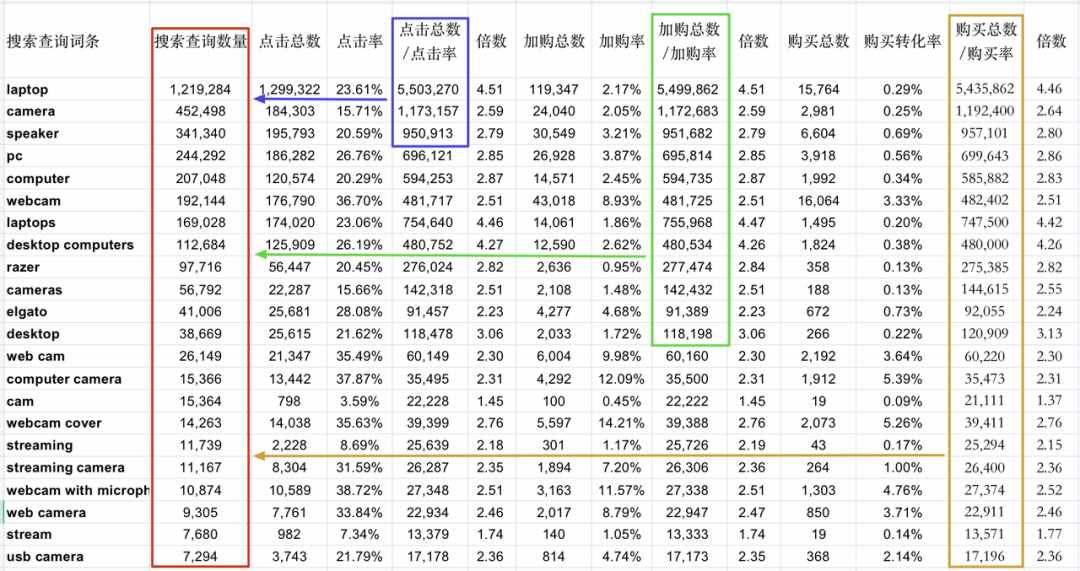
很容易发现,这三个数值与搜索查询数量并不相等,而且好像还有好几倍的差距。于是我们使用这三个值分别除以搜索查询数量,得到分别的倍数,如下图。
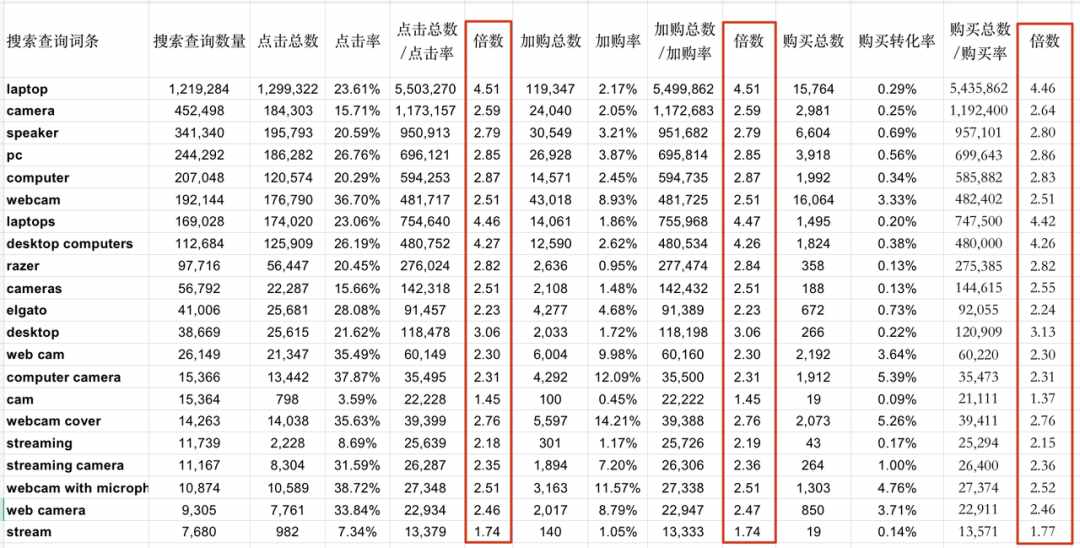
于是,诡异的地方出现了。这三个比值得到的值都是搜索量,亚马逊也给出了搜索查询数量,这两组数据理论上应该相等。
但它们并不相等,且通过比值算出来的搜索量比搜索查询数量都要大1.5-4.5倍不等。
所以问题就来了,两个理论都应该是搜索量,但为什么并不相等,而且中间还有好几倍的差距?谁才是真正的搜索量?谁又不是搜索量?
虽然亚马逊的指标解释通常都语焉不详,但我们把官方给的解释又通读了一遍之后(以下截图大家现在已经无法看到,因为已经更新了),发现了搜索查询数量真实含义的一点蛛丝马迹。
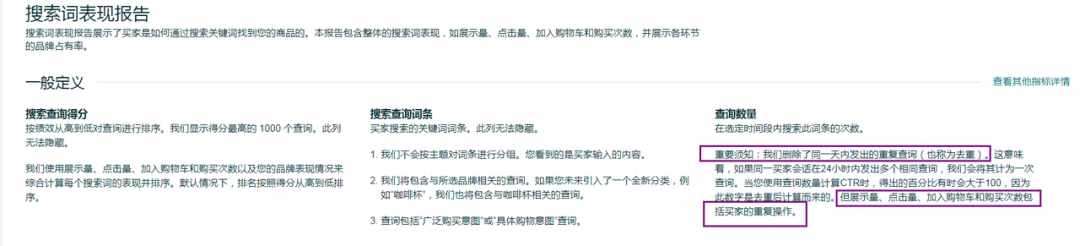
在这个截图里,亚马逊官方解释的是,搜索查询数量是同一个买家在24小时内发出的请求去重之后的数量。也就是说,这个搜索查询数量,如果是一天的数据,可以理解为某个词的搜索人数;如果是周或者月,则可以理解为周或者月的搜索人次。比如一个客户在一周的周一和周五都搜索了同一个词,那么这个客户在这一周会记2个搜索查询数量。
由于搜索词表现最细的颗粒度也是周,所以我们认为这个数据代表的就是搜索人次。
于是,在搜索查询数量和我们我们算出来的三个比值,显然那三个比值更像是搜索量。
什么才是真正的搜索量
那我们如何确定点击量/点击率、加购量/加购率、购买量/购买率得到的比值确实就是真正的搜索量呢?
证明的机会出现在了搜索词表现2.0版本,亚马逊在9月份左右升级到了搜索词表现2.0版本。
同样是22年7月份的数据,可以明确的看到,同一个词laptop的搜索查询数量比1.0版本的时候大了好几倍:1.0版本是1,219,284,2.0版本则是5,504,032。

而5,504,032这个数值,刚好和我们通过三组比值算出来的数值几乎一模一样,这显然绝非巧合。
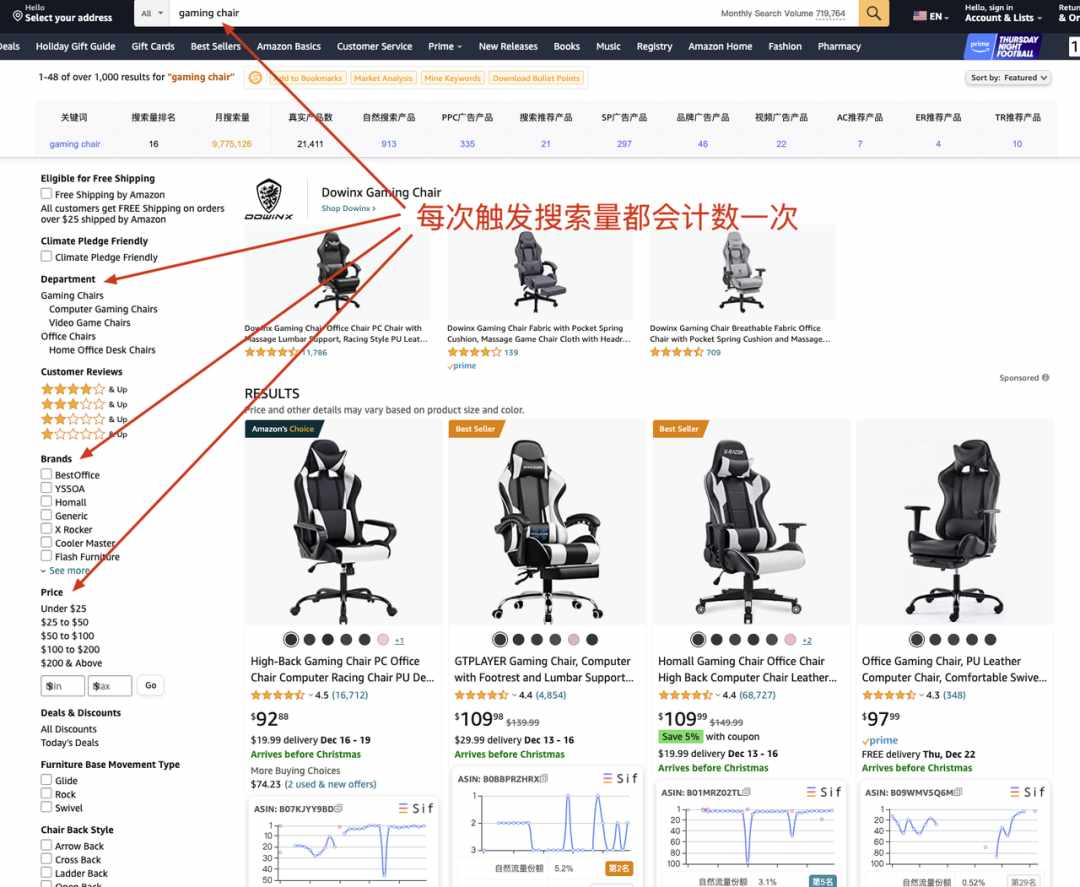
这个变化还是蛮大的,为什么会发生这个变化?我们注意到,亚马逊对查询数量做了新的定义。

这段话包含两个含义:
多次请求会重复计数,也就是一个关键词一个客户一天内查询多次,不会去重
翻页,也会算作是一次搜索请求
这两个特征,就和我们之前所了解的A9算法一模一样了。多次请求会重复计数、翻页会重复计数、在左侧增加任何筛选条件也会重复计数。
也就是说,之前1.0版本的确实不是搜索量,更像是搜索人次,而中间相差的倍数,就是代表一个词平均每个消费者会搜索几次。
如何证明商机探测器里的“搜索量”不是真的搜索量
现在,有了这个数据,请允许我们掷地有声地向大家证明,商机探测器的搜索量并不是真正的搜索量。这也算是我们对自己曾经的那份朴素的坚持的一份有力声明。
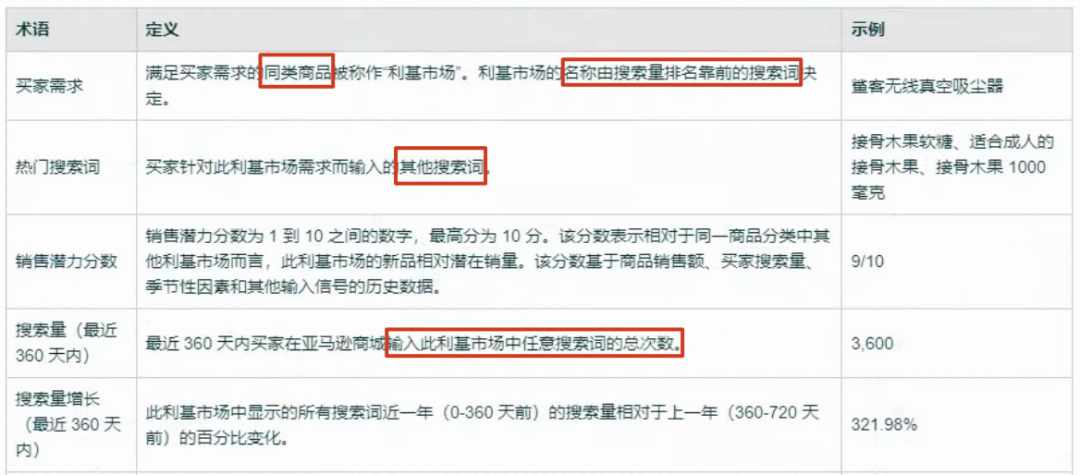
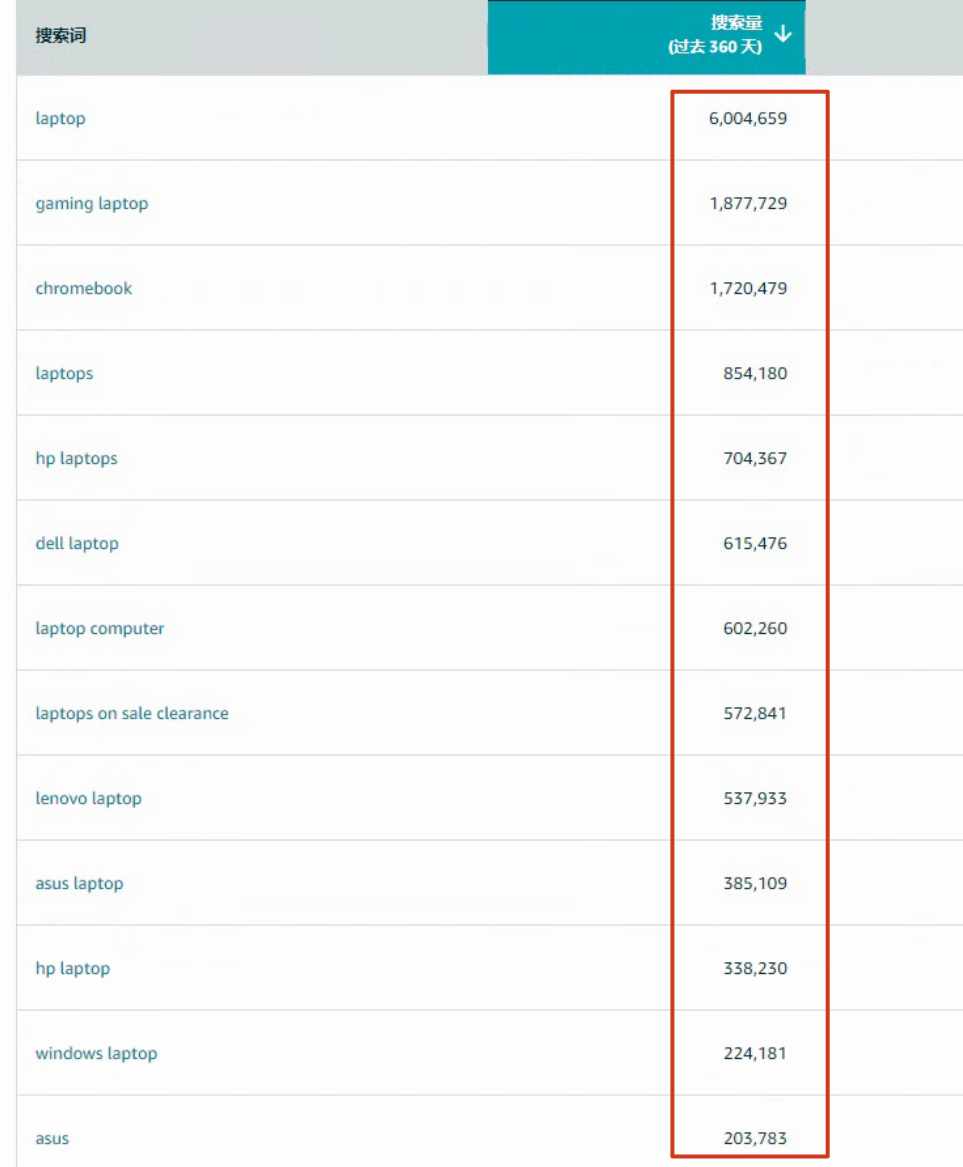
我们找到在搜索词表现里出现的第一个词laptop,去商机探测器找到对应的数据。
同样的关键词,商机探测器里显示过去360天的搜索量只有600万,平均一个月才50万。但这个词在搜索词表现里,今年7月份就有550多万的搜索量,很明显,商机探测器里的搜索量绝非真正的搜索量。
那商机探测器的数据到底代表的是什么含义呢?我们用数据做一下推理。
我们依然使用laptop这个词,我们来统计一下laptop这个词在商机探测器的7月份的数据。
由于商机探测器的“趋势”模块给的是细分市场的趋势,所以我们先大致统计laptop这个细分市场在7月份的搜索量,然后再根据laptop这个词在这个细分市场的360天的搜索量占比来大致计算laptop这个词在7月份的搜索量(相当于假设laptop这个词在laptop这个细分市场里的搜索量份额,在7月份的时候和360天里是大致相等的)。
下图是laptap这个细分市场的搜索量趋势。
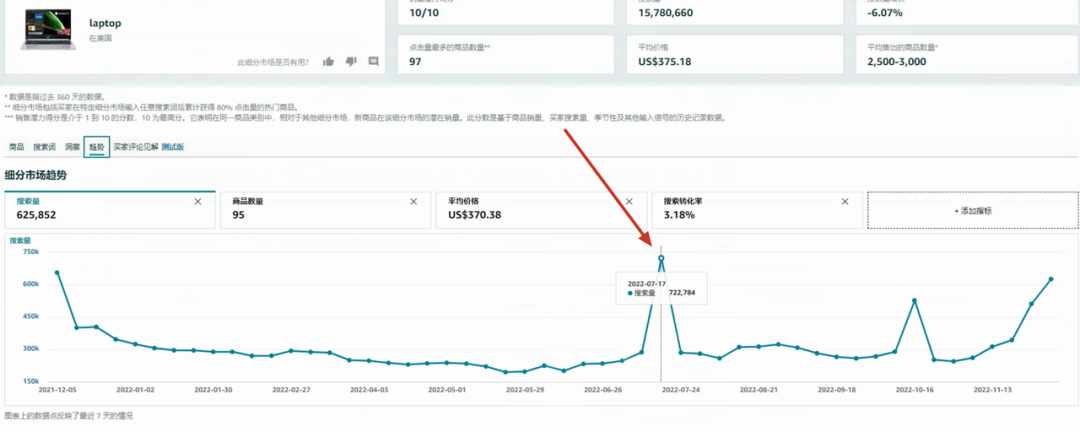
我们将laptop这个细分市场在过去一年的搜索量做一下记录,分别如下:
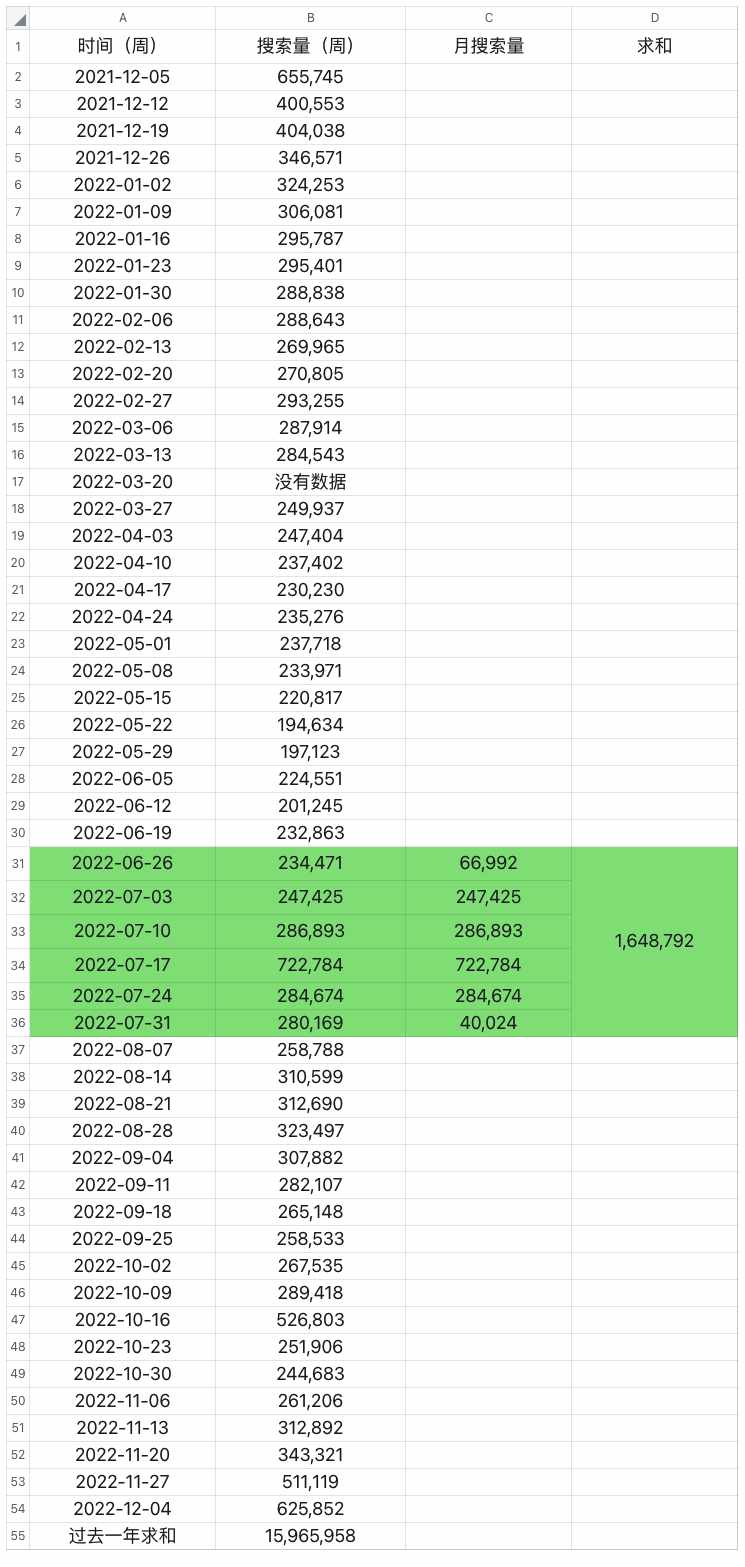
然后选择其中的7月份的数据进行统计。由于7月的第一周和最后一周只有部分天数在7月内,我们取它们所在当周的数据除以7,再乘以在7月内的天数,最终得到laptop这个细分市场在7月份的搜索量大致是1,648,792。
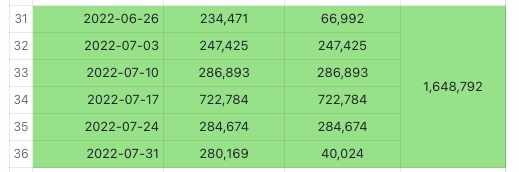
然后我们把laptop细分下市场的多个关键词360天的搜索量做一下求和,得到15,626,037(具体计算过程就不在这里贴出来了,我们直接用计算器加的)。
这个数据和过去一年的数据求和15,965,958大致相当。我们之所以要研究这两个数据,是害怕亚马逊在不同模块给出的数据又有差别,为保险起见,我们用上了可以用的所有数据做交叉验证。

而这两个数据不完全相等的原因,则是因为按周的趋势数据,从21年12月5日开始,到最新的一周2022年12月04号(最后一天是12月11号)那一周结束,比360天要多出几天,所以数据稍微大一点,属于正常范围。
根据360天的搜索量总和,我们算出laptop这个词的搜索量占比大致为6,004,659/15,626,037=38.43%。于是大致推测7月份1,648,792万的细分市场搜索量,laptop这个词的搜索量大致是1,648,792 * 38.43% = 634,049。
我们在搜索词表现中已经明确,7月份的搜索人次是1,219,284,搜索量是5,504,032。
634,049这个数据,比7月份实际上550多万的搜索量,仅有其1/9。差距如此之大,基本可以证明,商机探测器的搜索量,与真正的搜索量相距甚远,绝不可能是真正的搜索量。
但634,049这个数据又留下了一个新疑点:它比7月份laptop这个词在搜索词表现里的搜索人次1,219,284也差不多小了一半,这又是为何?
对于这个误差,我们有两种猜测:
商机探测器的搜索量,可能指的是搜索人数。也就是说,商机探测器里统计的,是在某一段时间内搜索过某个词的消费者数量。比如客户在某一周的周一和周五都搜索了laptop这个词,商机探测器只会计数1(统计周期内按同一个消费者去重);但搜索词表现里会计数2个搜索查询量,因为去重周期是24小时。
商机探测器指的是搜索人次,数据统计的误差来源于我们在这个过程中做的假设:我们认为laptop这个细分市场里的多个关键词,在1年的时间内搜索趋势都和这个细分市场是完全吻合的,同时在prime day那一个月的搜索量的增幅也是相等的。但实际上可能会有一些差异,或者有可能laptop这个最头部的词的搜索人次增加比例要比其他小的词大不少,所以实际上laptop这个词在7月份的搜索人次要比634,049这个数字要大。
这两种猜测我们倾向于第一种,因为后边还有新的疑点也指向这个猜测。
但不管商机探测器的数据代表的真实含义是什么,这不影响我们在前边得到的结论:虽然我们不完全确定商机探测器的数据是什么,但我们可以完全确定它不是搜索量。真正的搜索量是搜索词表现2.0里的搜索查询数量。
搜索量进一步探索过程中的新疑点
对于我们这些搞技术的人而言,知道什么是真正的搜索量,只是完成了真实的数据样本收集这一步。我们的目的,是要通过模型,来实现对真实搜索量的拟合,这样才能大面积应用在我们的产品之中。
接下来的部分,我们建议大家还是保持耐心继续阅读下去,因为这些思考决定着我们是如何通过模型推算搜索量的,而这个过程中,我们又发现了诸多疑点。
我们觉得有必要向大家分享我们的发现与疑惑,大家也可以据此评估,我们的模型的可信程度,方便大家在使用Sif时保持合理的预期,或者适当地调整预期。
我们的工作要进行下去,首先就面临一个困境。搜索词表现的数据是每个卖家自己店铺里的产品对应的关键词的数据,我们要把所有的关键词搜索量都覆盖到并保持更新,就需要非常大量的店铺,显然这个是没有办法做到的。
于是,很自然的,我们想到了在搜索词表现里寻找部分样本,然后通过ABA数据里的搜索排名来拟合搜索量曲线。这样只要使用ABA排名,就可以大致预估对应的搜索量了。
然而,当我们满怀期待,试着将搜索量与搜索排名关系对应的时候,第二个困境出现了:相同时期的关键词的ABA排名与搜索量并不是严格的线性关系。也就是搜索量排名靠前的,搜索量不一定大;而排名靠后的,搜索量也不一定比排名靠前的更小。
为了让大家有直观的感受,我们还是贴一下图。
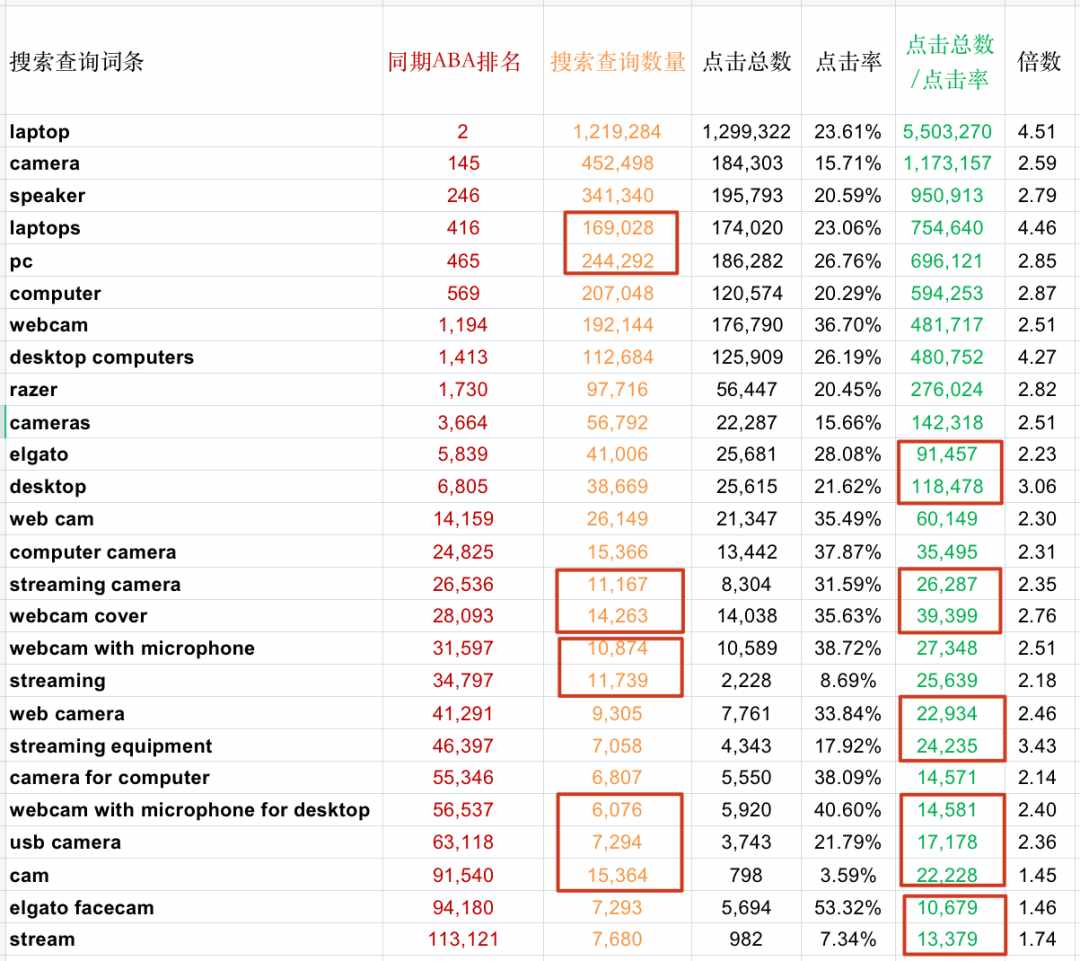
这张图中,红色那一列是ABA排名,橙色那一列是搜索人次,绿色那一列是搜索量,数据是按照ABA排名从小到大排序的。
红色框标出来的,就是理论上随着ABA排名从上往下变大(靠后),搜索人次或者搜索量应该跟着变小但实际上却在变大了的异常数据。
之所以把搜索人次的数据也一并对比,是因为在我们发现ABA排名与搜索量关系并不完全线性之后,我们猜测ABA排名是否可能是搜索人次的排名,但结果发现也不是。
一直以来,对于ABA的搜索频率排名到底代表什么含义,大家莫衷一是。现在这个研究结果,使得这个问题变得更加扑朔迷离。它既不代表搜索量排名,也不代表搜索人次排名。所以,ABA排名,到底是什么排名?
这个问题,需要用到我们之前在ABA上做过的一些研究,还要用到我们在对比搜索词报告2.0与ABA数据时的另一个发现。
关于ABA的研究是,我们发现一个有趣的现象,同样一个月内的ABA数据,月的ABA条数比周和天的条数都要少,显然ABA是有一定的过滤条件的。
这些现象指向一个我们推理得出的结论:ABA排名对应的数据,天数据最末尾的排名对应的值应该是1,周数据是7,月数据则大概是30(视当月天数而定)——具体推理逻辑可参考我们过去的文章《亚马逊ABA数据的一些有趣发现 》。
而搜索词报告2.0与ABA的联合研究的发现则是,相同月份的搜索词表现里的关键词,大约在搜索量略大于1000的时候,在ABA当月的数据里无法搜索到(这里研究的是美国站)。
比如下边两张图中的durable iPhone 13 case,在9月的搜索词表现中的搜索量为1232,但在9月的ABA中却找不到这个词。
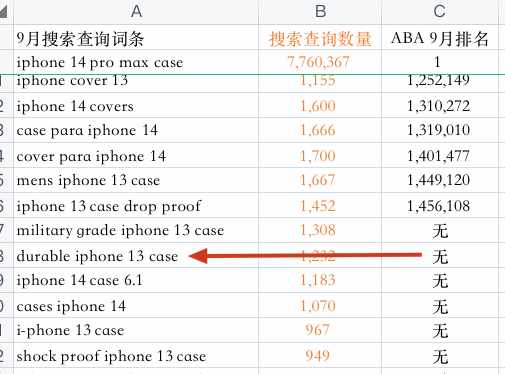
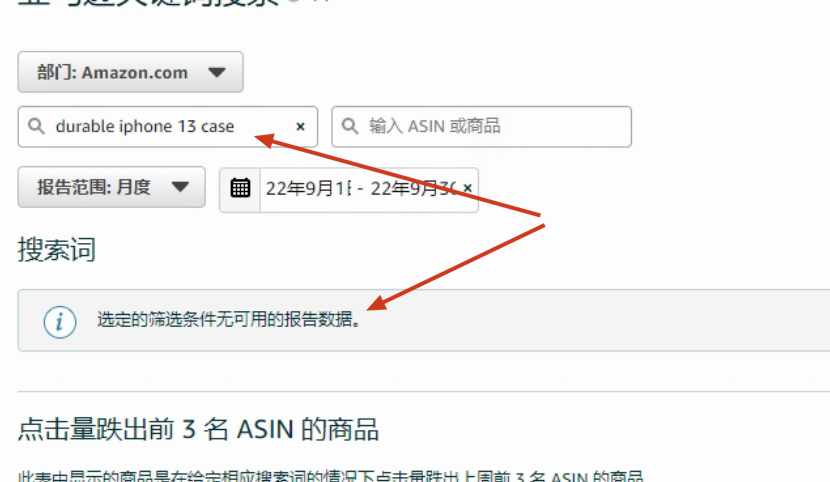
综合上边两个研究,我们可以大致推测ABA的排名背后对应的那个指标的值,与实际的搜索量之间大概相差30多倍(1000/30>30)。
30倍是一个差距非常巨大的数字,所以我们对ABA排名做了本文中最大胆的一个猜测:ABA排名是某一段时间内的PC端的搜索人数排名。
要证实这个猜测,我们需要做多个假设,让30倍这个数字看起来合理。
既然是猜测,就很可能会有问题。但我们猜测的思路,我们觉得也是很有参考价值的,所以我们也做一下说明:
首先,假设ABA的排名就是搜索量的排名,那么它们两者应该完全严格线性对应,没有任何误差,但实际情况不是。
接着我们很自然的就会猜测,是否是搜索词报告1.0里的搜索人次,结果也显示并不是。但没关系,我们将其作为一种可能性,再去叠加其他条件。
假设它如果是,误差大致会比3-5倍左右(之所以这个数字会比1.5-4.5大,是因为我们选择的样本是标品类的产品,而且行业集中度比较高,所以每次搜索时触发的搜索量不会太多,但非标品如服装行业的搜索量可能会比这个数字要大,因为每次消费者可能会翻更多的页码或者组合更多的条件。平均之后,倍数会比1.5-4.5要大。)
不是搜索人次,那是否可能跟商机探测器一样,是搜索人数呢?假设是,这会多带来2倍左右的误差(以商机探测器的经验)。我们也姑且作为一种可能。
之所以会做这个猜测,还有一个原因,是因为在ABA还未在亚马逊后台开放之前,我们从灰色渠道接触过大量的A9数据,A9数据里包含搜索人数和搜索量两个字段,但默认排序的字段是搜索人数,而不是搜索量。ABA是最早开放的数据,我们怀疑ABA继承了这个传统。
但以上两者相乘的倍数顶多也不到10倍,与30倍相去甚远,我们还得继续寻找。
刚才提到了A9数据,所以我们做了另外一个猜测:ABA的数据,可能并未包含移动端的搜索量。
之所以这么怀疑,是因为之前的A9数据在通过灰色渠道流入市场之后,大量的卖家觉得给出来的搜索量偏小,排名第一的词一个月也才几十万搜索量,于是各家服务商都不约而同地乘以了3-4倍,而这个3-4倍的差距,正是因为大家猜测这个数据并未包含移动端的搜索量。
猜测并未包含移动端还有另一个原因,是在2021年亚马逊在广告数据里突然增加了移动端的数据,导致大家后台的转化率数据突然暴跌。所以我们也怀疑,ABA数据里,可能只包含PC端的数据。
如果只包含PC端,那么PC端的流量目前大概只有25%的份额,如果是全平台,那么就还需要差不多乘以4。
现在我们将三个假设相差的倍数相乘,大致是[3,5]*2*4,差不多就是24-40倍之间,与30多倍的差距基本差不多。
关于这个猜测,亚马逊披露数据的节奏,也给了我们额外的一点信心。
从A9数据明确是搜索人数,且只包含PC端;到 ABA继承A9;再到商机探测器继承搜索人数,但增加了移动端;再到搜索词表现的1.0改为搜索人次;最后到2.0改为真实搜索量。整个数据披露的过程,越早出现的数据,与真实搜索量的差距就会越大,而每一个新模块似乎一开始都会继承上一个模块的一些数据,然后再进行升级。按照这个时间顺序,我们认为ABA的真实含义是某一段时间内的PC端的搜索人数排名,虽然大胆,但并非全无道理。
但假设就是假设,等我们有更多研究,有更重大的发现之后,我们再及时向大家同步。
接着我们讲一讲,在这些数据的基础之上,我们如何做搜索量模型。
Sif如何做搜索量模型
准确率如何
ABA排名并不是搜索量排名,是否ABA排名就完全没办法为搜索量做出贡献了呢?并不是。
大家看到,这个数据出现的偏差,并不是很大。在整体上,ABA排名与搜索量的关系依然是线性的,随着ABA排名的下降,搜索量整体也在变少,只是在相近的排名上并不呈现严格的大小线性关系。
所以,从一定程度上来讲,ABA数据依然具备其商业价值。在通过大量的店铺获取完全精确的搜索量,与使用ABA拟合出大致的搜索量之间,我们依然认为ABA是一个在工程上更具可行性与实用性的选择。
所以,Sif依然继续选择使用ABA排名来拟合搜索量。
但既然使用这种方法有局限,所以我们也把这个方法可能带来的问题,一一与大家做个说明。
第一,使用ABA搜索量,可能会导致在部分关键词上的搜索量与实际差距稍大。我们根据模型拟合出来的数据,发现有部分异常的点与曲线偏离较远,这种情况就是因为ABA排名与搜索量之间出现了较为异常的关系,猜测可能是某些用户或者网络爬虫大量搜索了某个关键词,导致这些关键词根据ABA排名推测的搜索量,与实际搜索量有几倍的差距。
比如2022年10月份的这两个词:cam和pc cam。cam在10月份的ABA排名是163,603名,pc cam在10月份的ABA排名是82,421。理论上,由于cam比pc cam这个词的排名要靠后8万多名,搜索量应该pc cam更大才对。
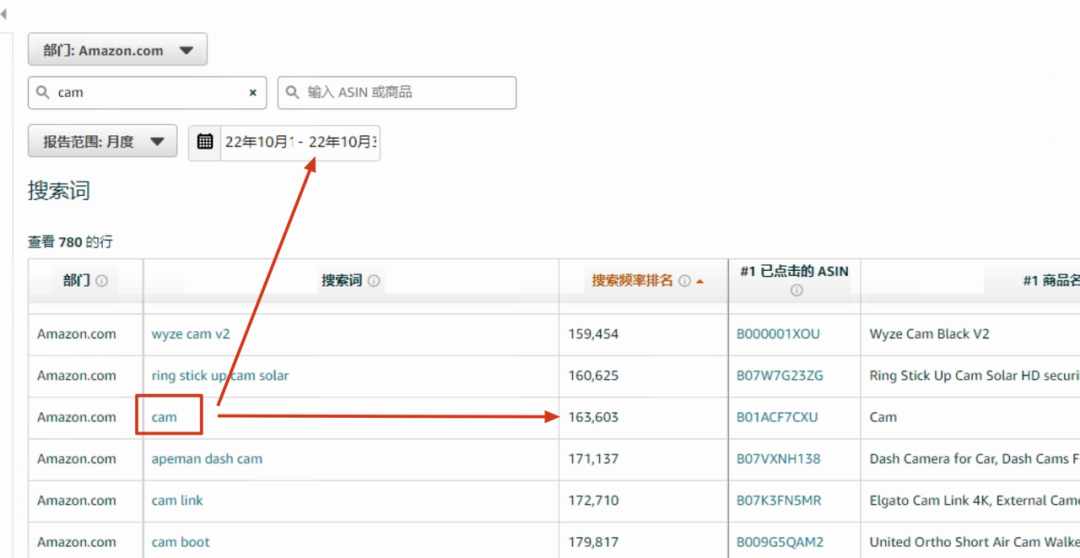

但cam却比pc cam的搜索量要大,cam的搜索量是15,157,pc cam反而只有10,401。
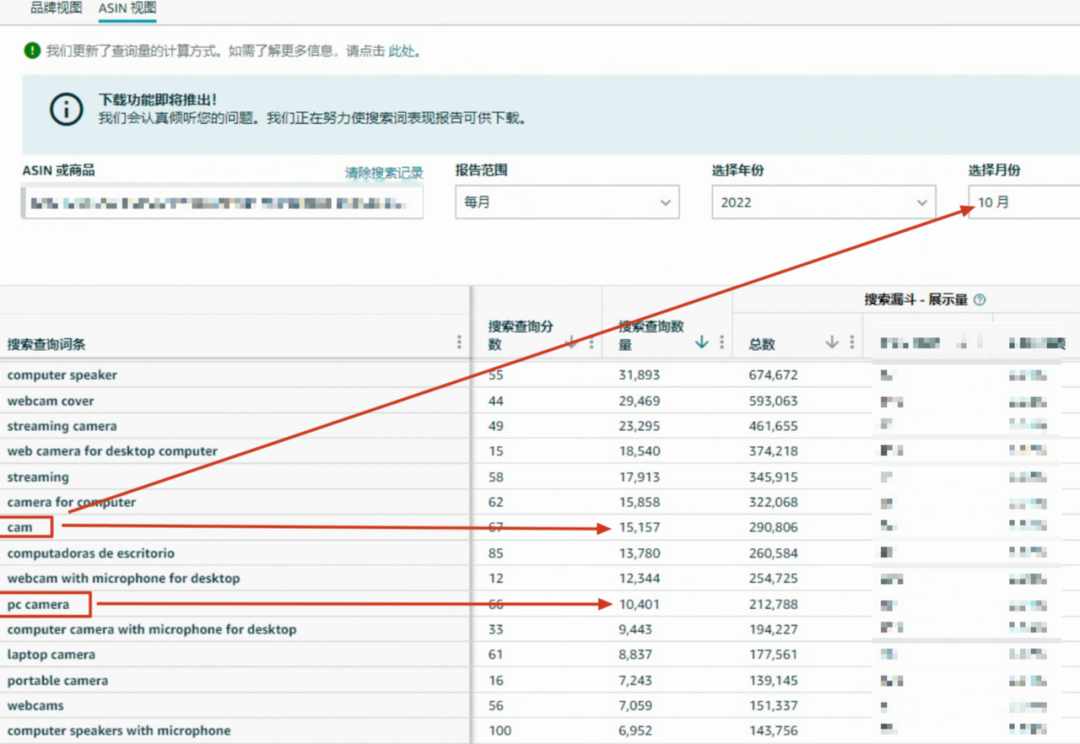
根据我们的模型,肯定pc cam的搜索量会更大,而且会比cam大不少,这就会导致误差变大。
第二,在不同的站点上,ABA排名的拟合准确率会有差异,大部分站点的大部分数据都可以做到80%以上的准确率,但部分站点却误差较大。
最典型的是英国站,ABA排名与搜索量之间的关系存在大量异常,尤其是下图中的②,该关键词的ABA排名是这一批关键词中是最靠后的,但搜索量却只比排名225的关键词略小。
这些异常导致我们很难直接用英国站的样本拟合模型,所以我们选择了人口数量和关键词数量十分接近的德国站的模型微调之后作为英国站的模型。
所以如果您发现Sif英国站的搜索量与搜索词表现相差很大,大概率是由这个原因导致的,我们正在想办法改善此模型。
第三,不同时间段的ABA排名对应的搜索量,与实际的搜索量差异会有区别。通常来讲,某个时间段ABA关键词条数越多,该期头部的关键词的搜索量就会越大,比如prime day对应的天/周/月的关键词条数就会显著多于平时,相同ABA排名的关键词的搜索量会比平时要大不少。
目前我们发现最为异常的是日本站的数据。prime day所在的月份的关键词条数只比平时略多一点,但大部分关键词的实际搜索量都有很大程度的提升,所以此时间段的搜索量,我们的准确率只有大致70%。我们后续会对异常月份的数据做特殊处理。
亚马逊数据使用建议
以上,便是我们对亚马逊搜索量的主要研究成果。从整个亚马逊数据模块的演进过程来看,大家也能发现,正确地认识和使用亚马逊的数据是一项非常艰巨的挑战。
所以,借这个话题,我们想就其中可能的原因跟大家做一个探讨,这些探讨有助于大家从整体上客观地认识亚马逊的数据,以及合理地管理自己的预期。
从我们上述的内容中可以看出,亚马逊后台的数据至少有这几个特点:
定义模糊,模棱两可
在很多指标的解释上仅仅只是点到为止,但关于统计口径的详细说明却非常少,导致大家认识不一,解读各异。
这个的主要原因应该是长期以来亚马逊都不是特别重视卖家端的服务,并且长期和卖家之间是互相对抗的博弈状态。但是随着流量见顶,市场从增量变到存量,亚马逊的态度也在逐渐改观,会从更多对抗的状态变为更多合作的状态,亚马逊已经做出的很多改变便可以发现其中的变化。
各个模块的统计口径不一致
这个问题非常严重,很多相同的名词在不同的模块,代表的含义差距巨大,导致大量数据想通过不同模块交叉使用时,发现完全不可用。这个槽点多到罄竹难书,我们找机会再跟大家分享。
出现这个的原因,市面上有一种说法是,亚马逊后台的各个模块是不同的团队负责的,缺乏统一的定义和说明,所以导致各做各的,我们使用的时候就要饱受不一致之苦。
这个说法我们觉得有一定道理,像亚马逊这样的大公司,后台服务有多个产品经理是很正常的事情。但是亚马逊也在开启大裁员,留下来的产品经理就要肩负更多模块的设计工作,也许这个会逐渐得到统一,让我们小小地期待一下。
数据都有不同程度的脱敏
这个倒是非常常见,几乎所有搜索引擎都会对数据做脱敏,比如Google、百度、淘宝用的都是将搜索量脱敏并做归一化之后的热度,亚马逊也一直保持着这个传统,比如销量用BSR代替,搜索热度用ABA排名代替等等。
这几乎是行业惯例,出于商业机密保护和数据披露法规等因素,各家平台都不会对外暴露真实的数据,所以我们不多说。
基于以上这些特性,我们有几个关于数据使用的建议,我们一直受益匪浅,希望对大家也有帮助。
第一,放弃对数据的绝对准确的执念。数据,只有对比才有意义。很多时候,绝对值并不重要,相对的趋势判断和对比更加重要,要用多维度和变化的视角看问题。就跟BSR和ABA排名都有其价值一样,甚至他们的价值比绝对的销量和搜索量都更加重要。大一点小一点,多一点少一点,别去计较这些鸡毛蒜皮的差异,关注那些更重要的东西。
第二,始终保持怀疑。不管是对亚马逊的数据,还是对大家在使用的服务商的数据,包括Sif的,我们都希望大家始终抱着谨慎的怀疑态度。拿到一个结果数据是简单的,但结果可能会骗人,多问是什么以及为什么,理解数据背后的逻辑,才不会被误导,才可以客观地评估数据的可信度,找到最适合的使用场景。
同时,我们也希望大家多怀疑自己,能够以开放的心态重新审视自己脑子里已有的东西,这也是我们想说的第三点。
第三,Stay hungry,stay foolish。说这句话不是为了哗众取宠,是在几年的从业经验中,我们发现一些卖家朋友的好奇心和研究精神还是少了一些,甚至连一些基础的亚马逊知识都还需要加强,但是却只能接受与自己认知一致的数据,十分让人惋惜。
数据的最大价值不是证明我们脑子里已知的东西,而是帮我们发现我们原来不知道和认知有问题的东西。大家用数据都是为了赚钱,证明自己牛逼除了自嗨之外,无益于帮我们赚更多的钱,只有那些我们还不知道的东西可以帮助我们赚更多的钱。
俗话说,我们只能赚认知之内的钱,我们的认知不拓展边界,能赚的钱就不会变得更多。
市面上一些服务商对亚马逊某一方面的理解是比很多卖家要更专业的,对他们保持质疑的同时,也要保持开放的心态学习,他们下过的功夫可以帮我们少走弯路或者避免重复发明轮子。
Sif的数据“价值观”
以上,就是这次我们想给大家分享的所有东西了。
每一个研究结果的结论得来都不容易,在整个过程中,我们既要一边保持对亚马逊数据的谨慎怀疑,一边又要面对对数据没有深入研究的客户的质疑,我们承受了巨大的压力。
但这些坚持最终证明都是值得的,我们可以很自豪的说,没有人比我们对亚马逊搜索量的研究更深入和执着。因为对这个数据从未放弃研究,我们也得到了很多其他的洞察,找其他时间我们再与大家做分享。
最后,为了做这些研究,不管我们经历了多少个孤独的夜晚,也不管我们为此承受了多大的压力,我们依然会一如既往地为大家做亚马逊数据的研究先锋,坚持为大家提供最具洞察力与最有实用价值的数据。
十分感谢郑小焦Megan、Miki、Y.Luomio、门与路、何轩、Kimi欣欣

我们建了一个亚马逊卖家交流群,里面不乏很多大卖家。
现在扫码回复“ 加群 ”,拉你进群。





热门文章
*30分钟更新一次